
In this tutorial, you will learn how to build a simple search using out-of-the-box functionality that comes with Umbraco V9. Implementing a site search is a key aspect of most projects. The good news is that implementing a search within Umbraco does not need to be complicated.
The reason why things within Umbraco are fairly simple is that Umbraco ships with a free third-party search provider called Lucene. Lucene is a widely used search index, used by hundreds of applications. The bad news is that Lucene is not a .NET native search provider. To fix this, Umbraco also ships with an out-of-the-box package called Examine. Examine is a .NET wrapper around Lucene that also hooks into the CMS. This means you can write a search in Umbraco using C# fairly quickly and simply. If you want to learn how to do this, read on 🔥🔥🔥
When you first install Umbraco three default search indexes will be created. These are:
ExtenalIndex: An index that contains all public pages and media on the siteInternalIndex: An index that contains all content created within the Umbraco backend. This index contains all published, save and schedule pages that have been created within the CMS.MembersIndex: An index that contains all members
All these indexes relate to files that will exist within your projects webroot. If you look within your webroot here:
Umbraco ➡ Data ➡ TEMP ➡ ExamineIndexes
You will find all the Lucene indexes. Using a free tool called Luke For Lucene you can browse the contents of these indexes if you want 🤔. A much simpler way to interact with the indexes is within the Umbraco backend. You can use the Examine Manager page to view the health status of each index and the contents of each index. It also provides the ability to re-index each index on-demand:
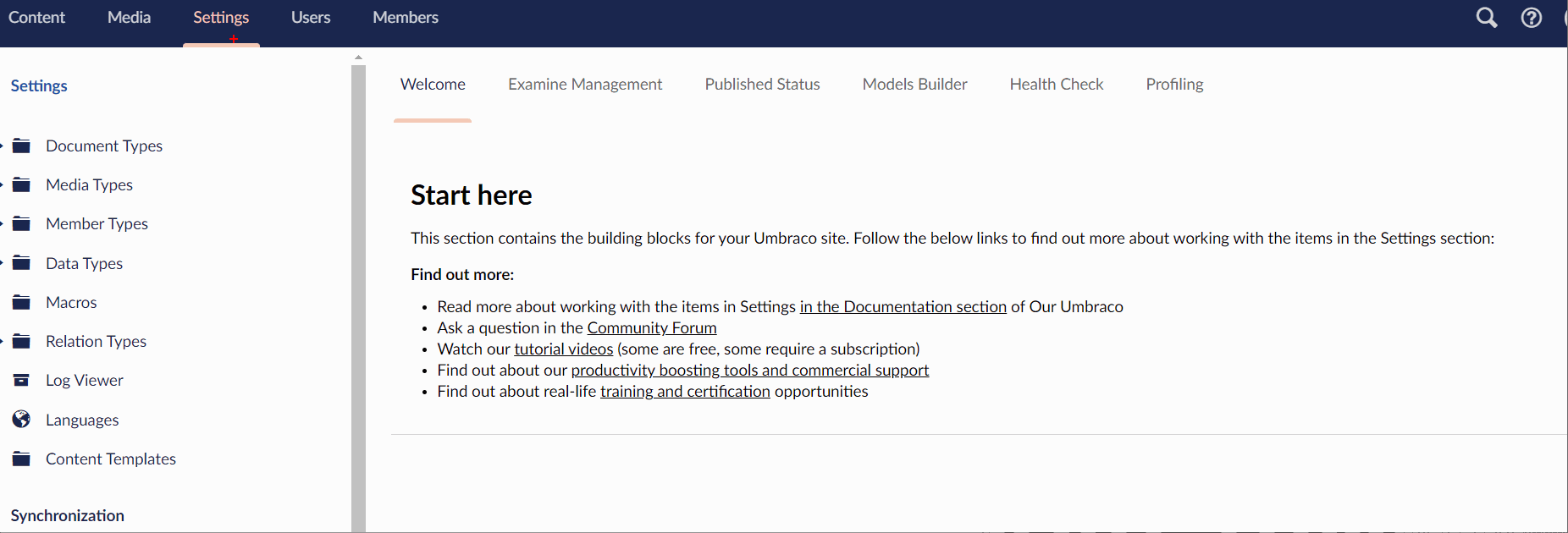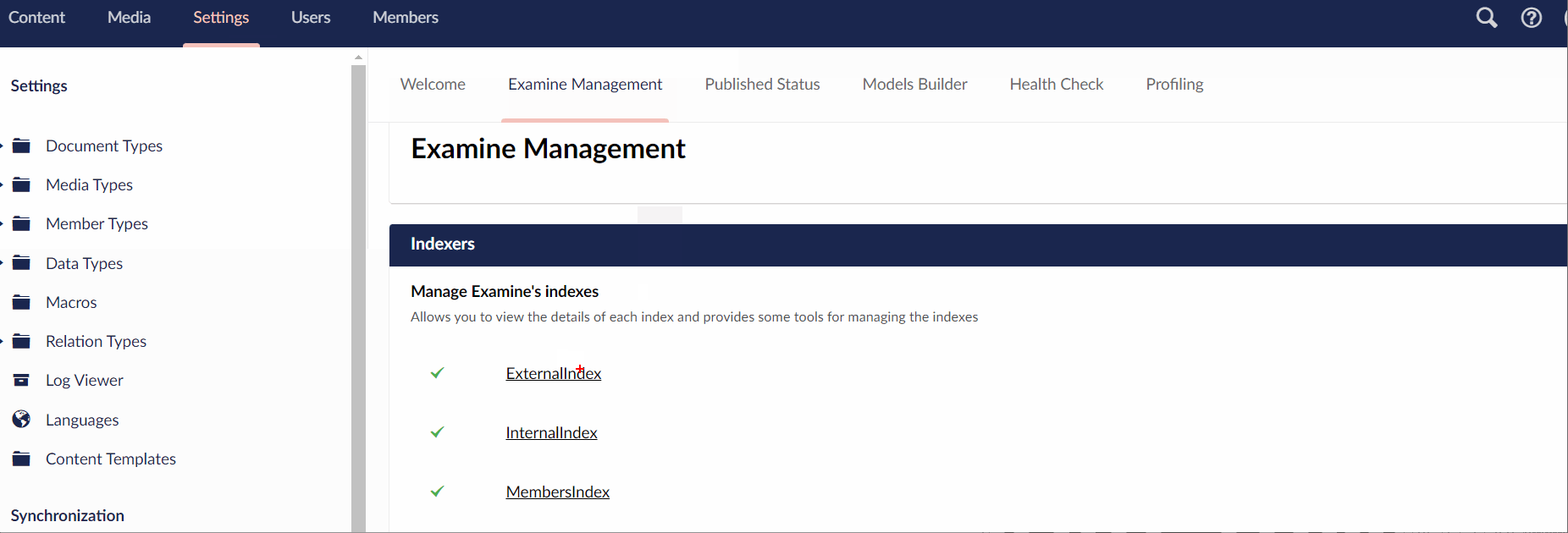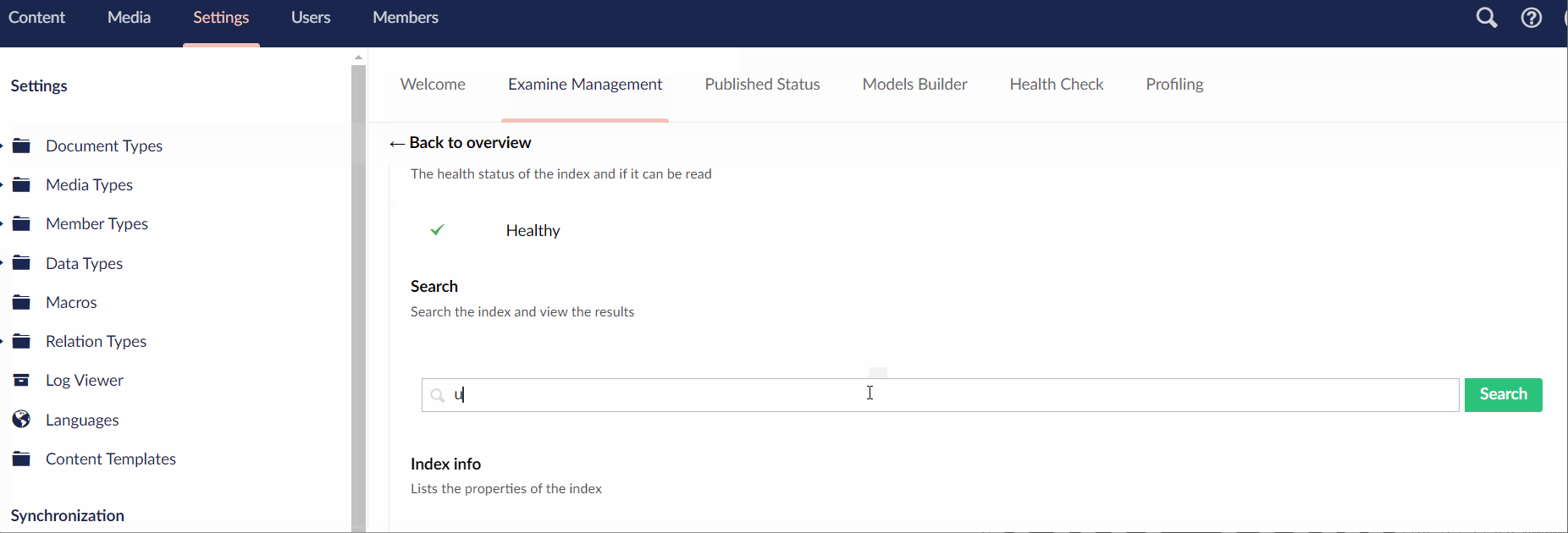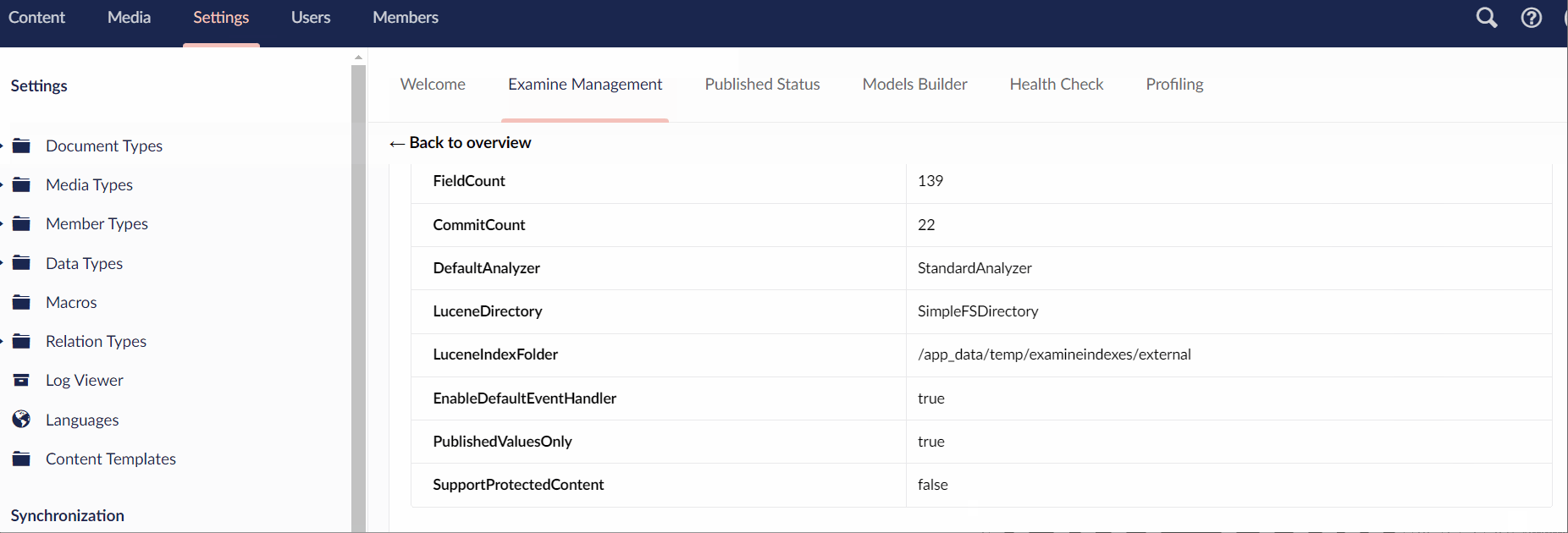
To build a search on your website, you will only want to return published content within your search results. This means you want to use the ExternalIndex to query for results. The next challenge is how to query the ExternalIndex 🤔
To access the external index in code, you can use the IExamineManager API. In Umbraco v9, you get dependency injection out-of-the-box. To access any of the Umbraco APIs, you can simply inject the API you want to work with as a constructor as a parameter, like this:
After you have access to the IExamineManager API you can use it to query the index. Using IExamineManager you can query any of the indexes defined within Umbraco. You can access the index using this code:
A handy thing to note is that you can use the UmbracoIndexes helper, found in Umbraco.CMS.Core.Constants, as a nice way to access the index names. Using UmbracoIndexes you get easy access to the index names for both ExternalIndexName and InternalIndexName. This helper will save you from having to manually type the index name yourself 💥
Building Search Queries
After you have established a connection with the index, you can then build up a search query. Examine manager provides a fluent API that allows you to intuitively build queries. An example of a query is shown below:
The Examine fluent API gives you a lot of power to build search queries that exactly match your requirements. You can chain commands together using operators:
And()Or()GroupedOr()
After each operator, you define a command. Examine ships with lots of commands that you can use. The most commonly used ones include:
NodeTypeAlias()Field()ParentId()
The most common query you will build is a query to filter the results by a certain document type and perform a search on either the page name or, on some content contained within a custom property defined on that document-type. To perform a search on the page name you search on the nodeName field. To search a custom property, you add the property alias into the field() operator
Once you have built your query, you use .Execute()`` to query the index.Executealso takes an optional parameter calledQueryOptions.QueryOptionscan be used to add pagination into the query. There are multiple ways to do pagination filtering when building a search page. You do not need to do the filtering while querying but you can. In some sites, doing one query and then caching the results in memory might be quicker than having the client constantly call back to the server per page request. If you want to do pagination at query time, you can use theskipandtakeconstructor arguments inQueryOptions`, like this:
skip and take work the same as the lambda equivalents. You could write the same filter using this code instead:
The difference with this approach is that the filtering is done after the index has been queried. In theory, this approach is less performant, however, in most instances, the difference might not be noticeable, so choose the technique that makes you happy 😊
After you perform a query, you will get access to the results. The results will not be a list of populated Umbraco page objects, instead, they will be a list of items of type ISearchResult. ISearchResult will give you the Umbraco Id and a search score for each result. In order to render the search results on the search page, you will need to query the Umbraco frontend cache to get the corresponding IPublishedContent object for each search result item.
You can do this using IUmbracoContextAccessor. You can access this API using dependency injection via a constructor. The code to convert search results into a Umbraco IPublishedContent object is shown below:
Using this code you now have a way to build a search page. When it comes to your websites architecture, my recommendation is to add the code to query the index within a service. You can then access the service from your search controller. The skeleton code to create this service is shown below:
To use this service within your search controller you should access it using dependency injection. To make this work, you will need to register the service with the dependency framework Umbraco uses. Registering a service is simple and involves using a Composer. The code to do this is shown below:
With your service defined, you can then create a controller for your search document-type. An example of how you can build this controller is shown below:
This controller inherits from the Umbraco RenderController. This special controller type that is supplied by Umbraco, will automatically allow you to perform route hijacking with a document type. The name of the controller needs to mirror the alias of the document type. On Line 36, notice how I define an action and pass in some parameters, searchTerm, andpage. One of the good things about usingRenderController` is the ability to add parameters without having to add define any routing rules. On-Line 39, the controller uses the service we created above to query the search index and return some results.
The final step is to create a view for the document type. In this example you would create a cshtml file here:
Views ➡ Search
I won't include the HTML to use within the view in this tutorial. This HTML will be bespoke to your design. In essence, you iterate through the result set and render some links on a page, simples 💥
You now know everything required to build a basic search using Umbraco CMS. Everything you have learnt about today comes with Umbraco out-of-the-box and is free. It is definitely possible to create a more powerful site search within Umbraco if you want to, however, in these situations, you might be better off not using Examine and using a tool like Algolia instead 😊. Happy Coding 🤘
